
こんにちは!エンジニアの岩松です。最近キャンプにハマってしまい、隙あらばキャンプに行ったり公園へピクニックに出かけているためインドアを自称するのが難しくなってきました。
今月はQAエンジニアの方がAssuredへジョインしたのですが、もともと同じチームで働いていたこともあったので8月の記事に引き続いて集合写真を撮ってみました。

また、以前TECH PLAY様のイベントで登壇をしたのですが、そこで参考文献として引用した「ドメイン駆動設計をはじめよう」にて翻訳をされた増田 亨さんにも取り上げていただいていたようです。同氏の著書も昔から参考にしていたため、とても嬉しかったです!
エンジニアが複雑な業務領域を学ぶことでより良いプロダクト開発に結びつけた事例紹介。内容が具体的ですばらしい。
— 増田 亨 (@masuda220) 2024年10月20日
これまでに存在しない業務フローは どう作っていくか?ドメインエキスパートやビジネスサイド、 チーム一丸となって取り組むドメインモデリング https://t.co/HGEzPCJsOw
 プロダクトを安心して使っていただくためのカイゼン(長尾)
プロダクトを安心して使っていただくためのカイゼン(長尾)
Assured では新機能開発とユーザー体験をよりよくするための細かなカイゼン活動を並行して取り組んでいます。 今回は、プロダクトを安心して使っていただくための取り組みを紹介します。
これまでは、セキュリティ調査を依頼する際に、ユーザーが効率よくタスクを完了できるように、必要な情報を入力してエンターキーを押すだけで調査依頼が完了する仕様になっていました。 ただ、効率を優先していたために独自のショートカットが誤操作を誘発していると、お客様からのフィードバックで気づきました。 誤操作を減らすために、今回はショートカットキーの調整と、確認ダイアログの追加を行いました。
ショートカットキーは、WCAG(ウェブコンテンツ・アクセシビリティ・ガイドライン)に基づいて、より多くの方が使いやすいように再定義しました。今回対象となるページに限らず、プロダクト全体で同じ操作となるように統一しています。
そして、確認ダイアログの追加についてです。 確認ダイアログは操作の取り消しができない場合に表示することが推奨されていますが、今回は取り消しのできる操作でしたが、追加をしています。 「調査の依頼」というアクションを取り消すこと自体は簡単ですが、裏側では操作依頼を受け取ったプロバイダー企業様へのキャンセルなどコミュニケーションが必要になるためです。 とはいえ、確認ダイアログが多くなることで操作の邪魔になるケースも発生するため、今後はデザインシステムなどを利用し、ダイアログを使うべき場所や基準を定義していくつもりです。
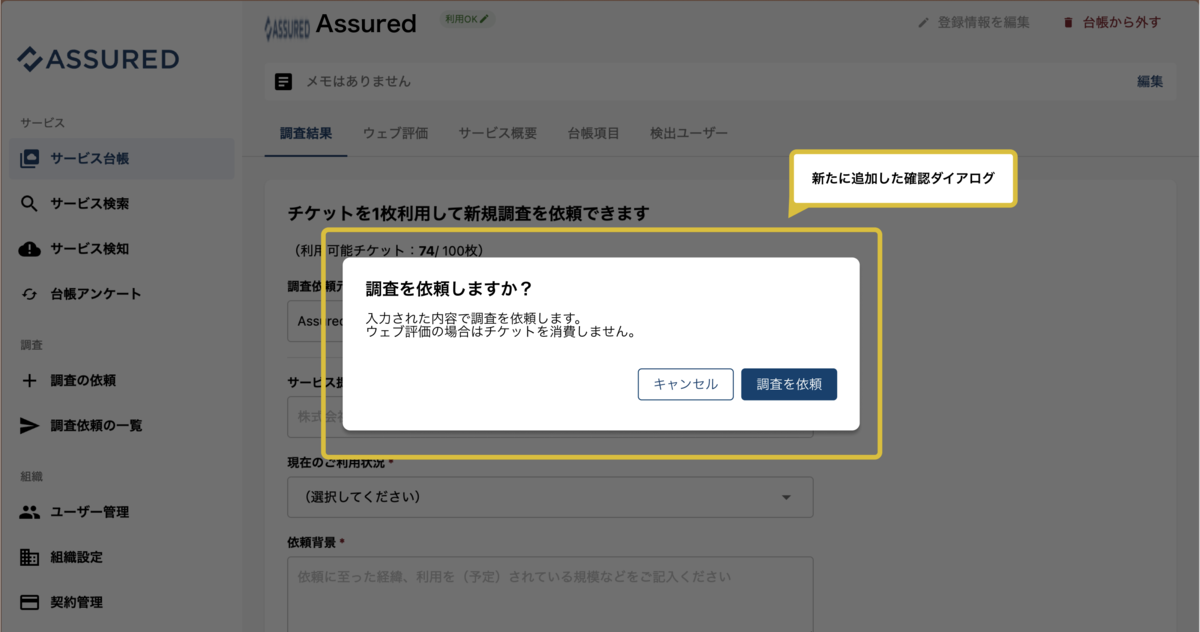
細かな部分ではありますが、Assuredが目指している「デジタル社会におけるインフラ」を実現するためには、プロダクトの操作ひとつひとつも重要だと思っています。 引き続き、新たな価値提供と足元のカイゼン活動を両輪で進めることで、さらに使いやすく、信頼されるプロダクトに成長させていきたいです。
 KPI管理のためにBigQueryを活用したデータ基盤の強化 (オリバー x 大方)
KPI管理のためにBigQueryを活用したデータ基盤の強化 (オリバー x 大方)
Assuredではリリース当初から組織全体でデータを基にKPIを指標にした改善に取り組んでいます。本番の実データは、Google Cloud PlatformのDatastreamやETLツールを使って安全にBigQuery(以下、BQ)に同期され、部署ごとにKPI設定や施策のモニタリングが行われてきました。リリースから約2年が経過し、ありがたいことに多くの企業様にご導入いただいている中、チームも拡大し、各部署や施策ごとに計測すべき指標も多様化しています。
例えば、セキュリティチェックシートの調査には、カスタマーサクセス、セキュリティ評価、プロダクト開発といった複数のチームが関わっていますが、調査申請から納品までのリードタイムの定義がチームごとに異なっていました。結果として、「リードタイム」を話しているつもりでも、チームごとの定義が異なるため、同じ指標を共有しにくく、過去比較や施策の評価にズレが生じていたのです。このような状況では、適切な意思決定を行うことが難しくなってしまいます。
この課題を解決するため、まずBQの実データを基準とした指標の再定義から着手しました。各チームの業務フローを詳細にマッピングし、タッチポイントを特定することで、ボトルネックを発見。その上で、統一された定義を作成し、チーム間での合意形成を進めていきました。さらに、過去からデータをタイムシリーズで同期していたことで、以前の施策の結果を新しいKPIと照らし合わせ、ビフォーアフターの比較を行うことも可能になりました。
技術的な実装では、BigQueryの特徴を活かし、ARRAYとSTRUCTを活用した時系列データの効率的な管理を行いました。例えば、以下のようなクエリで注文ステータスの管理を実現しています:
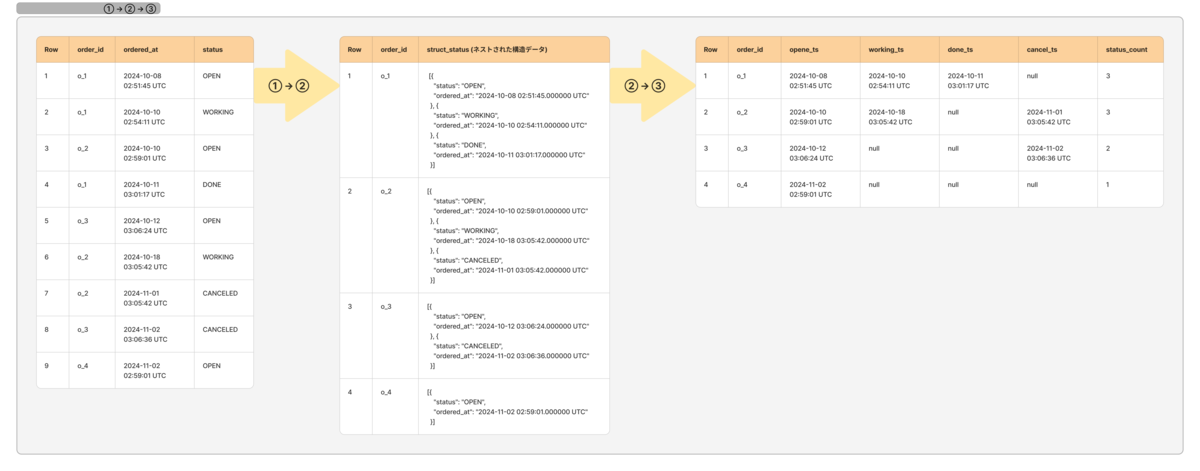
ネストした構造化データの扱い方 のサンプルクエリー
-- ① オーダーデータのサンプル WITH orders AS (SELECT "o_1" as order_id, TIMESTAMP '2024-10-08 2:51:45' as ts, 'OPEN' as status UNION ALL SELECT 'o_1', TIMESTAMP '2024-10-10 2:54:11', 'WORKING' UNION ALL SELECT 'o_2', TIMESTAMP '2024-10-10 2:59:01', 'OPEN' UNION ALL SELECT 'o_1', TIMESTAMP '2024-10-11 3:01:17', 'DONE' UNION ALL SELECT 'o_3', TIMESTAMP '2024-10-12 3:06:24', 'OPEN' UNION ALL SELECT 'o_2', TIMESTAMP '2024-10-18 3:05:42', 'WORKING' UNION ALL SELECT 'o_2', TIMESTAMP '2024-11-01 3:05:42', 'CANCEL' UNION ALL SELECT 'o_3', TIMESTAMP '2024-11-02 3:06:36', 'CANCEL' UNION ALL SELECT 'o_4', TIMESTAMP '2024-11-02 2:59:01', 'OPEN'), -- ② ネストした構造化データのサンプル arr_struct_tbl AS ( SELECT order_id, ARRAY_AGG ( STRUCT( status, ts)) AS struct_status FROM orders GROUP BY order_id ORDER BY order_id ASC ), -- ③ ネストした構造化データをstatus毎のtsで正規化したテーブルサンプル orders_2 AS ( SELECT order_id, (SELECT ts FROM UNNEST(struct_status) WHERE status = 'OPEN') AS opene_ts, (SELECT ts FROM UNNEST(struct_status) WHERE status = 'WORKING') AS working_ts, (SELECT ts FROM UNNEST(struct_status) WHERE status = 'DONE') AS done_ts, (SELECT ts FROM UNNEST(struct_status) WHERE status = 'CANCEL') AS cancel_ts, ARRAY_LENGTH(struct_status) AS status_count FROM arr_struct_tbl ) -- ① オーダーデータのサンプルの出力確認 -- SELECT * FROM orders; -- ② ネストした構造化データのサンプル -- SELECT * FROM arr_struct_tbl -- ③ ネストした構造化データをstatus毎のtsで正規化したテーブルサンプル -- SELECT * FROM orders_2
また、日付関数を使用することで、柔軟な期間集計も可能になりました
| Row | v_date | wk_start | wk_end | wk_num | month | year |
|---|---|---|---|---|---|---|
| 1 | 2024-05-22 | 2024-05-20 | 2024-05-26 | 20 | 5 | 2024 |
| 2 | 2024-05-23 | 2024-05-20 | 2024-05-26 | 20 | 5 | 2024 |
| 3 | 2024-05-24 | 2024-05-20 | 2024-05-26 | 20 | 5 | 2024 |
| 4 | 2024-05-25 | 2024-05-20 | 2024-05-26 | 20 | 5 | 2024 |
| 5 | 2024-05-26 | 2024-05-20 | 2024-05-26 | 21 | 5 | 2024 |
| 6 | 2024-05-27 | 2024-05-27 | 2024-06-02 | 21 | 5 | 2024 |
| 7 | 2024-05-28 | 2024-05-27 | 2024-06-02 | 21 | 5 | 2024 |
| 8 | 2024-05-29 | 2024-05-27 | 2024-06-02 | 21 | 5 | 2024 |
| 9 | 2024-05-30 | 2024-05-27 | 2024-06-02 | 21 | 5 | 2024 |
| 10 | 2024-05-31 | 2024-05-27 | 2024-06-02 | 21 | 5 | 2024 |
ネストした構造化データの扱い方 のサンプルクエリー
-- 利用した 日付関数の例のサンプル WITH -- 日付のサンプルデータ gen_dates AS ( SELECT v_date FROM UNNEST(GENERATE_DATE_ARRAY('2024-05-22', DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))) AS v_date ) SELECT v_date, -- まるめこみ用補助データ DATE_TRUNC(v_date, WEEK(MONDAY))AS wk_start, #v_dateの週の開始日(月曜日が開始日の場合) LAST_DAY(v_date,WEEK(MONDAY)) AS wk_end, #v_dateの週の終わり日(月曜日が開始日の場合) EXTRACT(WEEK FROM v_date) AS wk_num, #v_dateの年中の週番号 EXTRACT(MONTH FROM v_date) AS month, #v_dateの月数 EXTRACT(YEAR FROM v_date) AS year, #v_dateの年数 FROM gen_dates
これらの取り組みにより、チーム間での共通理解が深まり、データに基づく意思決定の質が向上できます。レポート作成時間の短縮やチーム間連携の円滑化、リソース配分の最適化といった具体的な成果も得られることを期待しています。
今後も、データで語れる組織を大切にし、より精緻な分析と迅速な意思決定をしていける基盤をチームで作っていきます。新しいビジネス要件や技術トレンドに応じて、柔軟に進化させていくこと、データドリブンな組織づくりに向けて、継続的な改善を進めていきたいと考えています。
 OSTをより良くするために工夫していること (内山)
OSTをより良くするために工夫していること (内山)
ちょっと前にXで「エンジニア懇親会あるある」が盛り上がっていましたが、たぶん皆さんも経験あるんじゃないでしょうか?(僕もよくあります)
社内でエンジニア懇親会でよく起きることについて話したら盛り上がったので20個ほどあるあるをまとめました!
— 名人|マナリンクCTO (@Meijin_garden) 2024年11月1日
エンジニア懇親会あるある|meijin https://t.co/tPd4QhhBvc #zenn
僕たちもプロダクトエンジニアOST in 渋谷というイベントを運営していますが、OSTはトピック毎に分かれてディスカッションするという形式です。最初から最後まで懇親会の様なイベントのため、ネガティブな「懇親会あるある」が発生してしまうと参加者の体験が悪くなってしまうので、できるだけ発生しない様に以下の工夫をしています。
- 最初のルール説明で発言へのハードルを下げる

- 全トピックに運営の人を散らばらせてファシリテーターとして振る舞う
- 最初に軽く全員の自己紹介をする
- テーブルに近づいてきた人を呼び止める
- テーブルに途中から参加した人には会話の流れを簡単に説明する
これでもあるあるは発生してしまうと思うので、アンケートでフィードバックをもらったり、僕自身も他のイベントに参加してよかった点を持ち帰ったりと改善を続けていき、参加者全員が会話に参加できて、何かを持ち帰ってもらえるイベントにできたらと思っています。
余談ですが、Xのアカウント交換に手間取るという話はプレーリーカードもいいですが、こちらも手軽でおすすめです。
交流会出るときは名刺交換より
— とつか|㍿カンリー (@totty_1113) 2024年8月28日
スマホにこの壁紙が最強だな😎 pic.twitter.com/xBr3rHyjU4
おわりに
毎月行動指針の記事を書く際に、それぞれがやってきたことを棚卸ししているのですが、毎回良い取り組みが出てくるのは改めてすごいことだなと感じています。しかし当の本人は意外とそれを認識していなかったりするので、みんながちゃんと認識する、仕事を讃えあう機会としてのテックブログも良いものだなと感じているところです。
最後に、私たちと一緒にプロダクトづくりを共にして下さる仲間を募集しています! 今回のブログを読んで、少しでも興味を持ってくださった方は、ぜひ採用情報をご覧ください。