 こんにちは!エンジニアのオリバーです。最近、個人で翻訳するときに ChatGPT に英訳、和訳させてみることが多くなってきたこの頃です。
こんにちは!エンジニアのオリバーです。最近、個人で翻訳するときに ChatGPT に英訳、和訳させてみることが多くなってきたこの頃です。
久々に少し長めの技術記事を書かせていただきました。最近のトレンドである(と思っている)多様なデータを素早く安全に Google Cloud Platform (GCP) 上で活用するための記事になっています。記事後半には Terraform のサンプルと一緒に構成の説明がありますので興味ある方は最後まで読んでいただければと思います。
直近、GCP の BigQuery にアプリケーションのデータをニア・リアルタイムで同期できる Change Data Capture (CDC)のマネージドサービス、Datastream for BigQuery を利用する機会がありました。今回使用したデータソースは外部からのアクセスを許可していない構成だったのですが、こういったプライベート接続が必要な Datastream for BigQuery の構成はサンプルや情報が少ないため少し苦労しました。今回の記事で紹介する設定方法が、同様の対応を検討されている方々への一例になればと思います。
- Datastream for BigQueryとは
- Public Cloud SQL と Private Cloud SQL での構成の違い
- Private Cloud SQL での構成
- 導入前に検討しておく注意点
- おわりに
Datastream for BigQueryとは
GCP が提供するマネージドな CDC サービスである Datastream の BigQuery 向けソリューションです。リレーショナルデータベース(RDBMS)のデータ変更をキャプチャし、BigQueryへシームレスにレプリケーションしてくれます。対象は、MySQL, Oracle, PostgreSQL などの RDBMS と Google CloudSQL や AWS RDS などのホスティングからもレプリケーションが可能です。CDC が可能なサービスは市場に多くありますが、連携したい解析基盤とデータソースが GCP にある Assured にとっては同じプラットフォーム内で完結できる Datastream for BigQuery を検証して採用しました。また、以下の様な点でデータの転送やレプリケーションに関して必要なサーバーやそれに伴うコーディングが基本的には必要ないのも利点でした。
| Datastream for BigQuery | その他のBigQuery へのレプリケーションができるソリューション | |
|---|---|---|
| サーバーリソース | 自動的にスケールアップとスケールダウンを行うサーバーレス アーキテクチャ | 関連サービスが稼働する環境を自身で用意または設定が必要。スケーリングなども自身で設計、構築が必要 |
| リソース管理 | 追加リソース不要。基本的には Datastream の サービスのみで完結する。 | 関連ツールやバッチジョブを稼働させるサーバーリソースが必要 |
| データソースとの連携 | End-to-End の設定を Datastream の管理コンソールで一括管理可能 | 個別に設定して、個別に管理する必要がある |
| データの鮮度 | ほぼリアルタイムでのCDC同期が可能 | 自身で構築、保証。使用するツールや環境に依存する |
Public Cloud SQL と Private Cloud SQL での構成の違い
実際の構成説明に入る前に、ベストプラクティスにある Public Cloud SQL への接続ケースと Private Cloud SQL への構成の違いにについて解説します。
Public Cloud SQL との接続
GCP のクイックスタートでは、以下のように外部アクセスが可能なデータソースをもとに Datastream を設定することになるのではないでしょうか。事前に Datasrtream で BigQuery に同期する設定を見ておきたい方は、3月の頭にGoogle Japan Team が翻訳した記事がありますのでよかったら読んでみてください。

Private Cloud SQL との接続
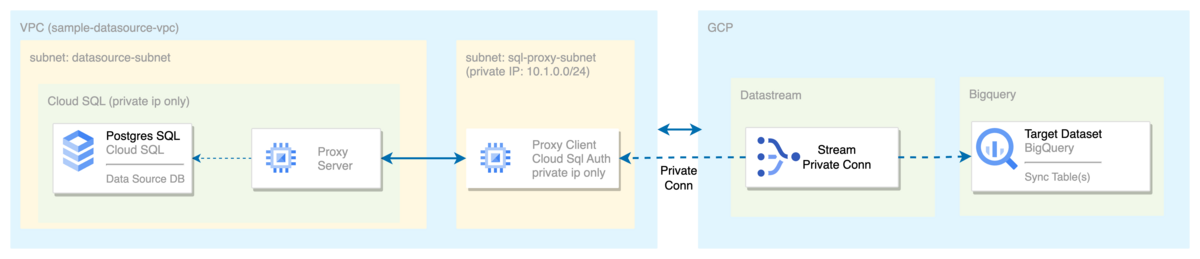
以下の図は Private IP のみの Cloud SQL (PostgreSQL) をデータソースとした際の構成です。上記と違うのは、Private Cloud SQL に接続するための Client をインストールしたインスタンスがあり、Datastream の設定内容に「プライベート接続」の設定が追加されている点です。接続に必要な Cloud SQL Auth Proxy Agent がインストールされたリソースは GCE の VM Instance を利用しています。

Private Cloud SQL での構成
実際に 以下の Private Cloud SQL との接続の設定をしていきます。
各設定をTerraform リソースの記述で解説していきます。実際に試す際のネットワーク、 FW、IAMの設定はご自身の環境に合わせてください。
1. VPC の作成
Private IP でのアクセスのみに限定した Cloud SQL instance を作成するための VPC の作成とPrivate IP に限定した Cloud SQL へアクセスするための Proxy Instance 用の Subnet の作成を一緒に行います。
// Create sample VPC resource "google_compute_network" "sample-datasource-vpc" { name = "sample-datasource-vpc" project = "<YOUR_PROJECT_ID>" auto_create_subnetworks = false } // Create Subnet for Proxy Instance resource "google_compute_subnetwork" "proxy-client-subnet" { ip_cidr_range = "10.1.0.0/24" name = "sample-proxy-client-instance" network = google_compute_network.sample-datasource-vpc.self_link private_ip_google_access = true project = "<YOUR_PROJECT_ID>" region = "<YOUR_REGION>" }
2. Private Cloud SQL の作成
Private IP からのアクセス制限した Cloud SQL (PostgreSQL) を作成する際に、Datastream の Stream の読み取りに必要な cloudsql.logical_decoding の database flag を事前に有効化しておく必要があります。(すでに運用している Cloud SQL PostgreSQL でも変更は可能です。フラグを変更する際は再起動する可能性があります。)
resource "google_compute_global_address" "private_ip_address" { provider = google-beta project = "<YOUR_PROJECT_ID>" name = "sample-private-ip-address" purpose = "VPC_PEERING" address_type = "INTERNAL" prefix_length = 16 network = google_compute_network.sample-datasource-vpc.self_link } resource "google_service_networking_connection" "private_vpc_connection" { provider = google-beta network = google_compute_network.sample-datasource-vpc.self_link service = "servicenetworking.googleapis.com" reserved_peering_ranges = [google_compute_global_address.private_ip_address.name] } resource "random_id" "db_name_suffix" { byte_length = 4 } data "external" "current_ip" { program = ["bash", "-c", "curl -s 'https://api.ipify.org?format=json'"] } resource "google_sql_database_instance" "private-instance" { provider = google-beta project = "<YOUR_PROJECT_ID>" region = "<YOUR_REGION>" name = "<YOUR_PRIVATE_DB_INSTANCE_NAME>" database_version = "POSTGRES_14" depends_on = [google_service_networking_connection.private_vpc_connection] settings { tier = YOUR_TIRE // Private IP のみからのアクセスを制限するための設定 ip_configuration { ipv4_enabled = true private_network = google_compute_network.sample-datasource-vpc.self_link // 必要に合わせてCloudSQL Instance へ外部からアクセスするためのIP登録 しない場合は設定の必要なし // 認証ネットワークに関して: https://cloud.google.com/sql/docs/postgres/authorize-networks#authorized-networks authorized_networks { name = "test-access" value = "${data.external.current_ip.result.ip}/32" } } // Datastream の ストリーミングする際に必要な postgres の機能を有効化 // https://cloud.google.com/sql/docs/postgres/replication/configure-logical-replication database_flags { name = "cloudsql.logical_decoding" value = "on" } } }
3. Datastream のプライベート接続の作成
step 1 で作成した VPC と Peering するための IPアドレス を振り当てます。
resource "google_datastream_private_connection" "datastream-priv-conn-postgres" { project = "<YOUR_PROJECT_ID>" display_name = "datastream-priv-conn-postgres" location = "<YOUR_REGION>" private_connection_id = "datastream-priv-conn-postgres" vpc_peering_config { vpc = google_compute_network.sample-datasource-vpc.id subnet = "10.2.0.0/29" }
4. Cloud SQL Auth Proxy Client のインスタンスの作成
Private な Cloud SQLと接続するため、外部IPアドレスを設定しないインスタンスを作成し Proxy として利用します。
そのため、インスタンスに Proxy Agent を外部からインストールするためにネットワーク設定を事前に設定する必要があります。
(外部からのアクセスができても良いインスタンスの場合は、ネットワークの設定をスキップして、インスタンス作成から始めてください。)
リソースに必要な最小限の権限は以下です。(付与する Role はあくまで一例として、ご自身の環境に合わせてください)
- Cloud SQL クライアント (Cloud SQL Client)
- サービス アカウント ユーザー (Service Account User)
- モニタリング指標の書き込み (Monitoring Editor)
- ログ書き込み (Logs Writer)
// Create a NAT router for fetching from internate resource "google_compute_router" "sample-datastream-proxy-nat-router" { name = "sample-datastream" project = "<YOUR_PROJECT_ID>" region = "<YOUR_REGION>" network = google_compute_network.sample-datasource-vpc.self_link } resource "google_compute_router_nat" "sample-datastream-proxy-nat-config" { name = "sample-datastream-proxy-nat-config" project = "<YOUR_PROJECT_ID>" router = google_compute_router.sample-datastream-proxy-nat-router.name region = "<YOUR_REGION>" min_ports_per_vm = 16 nat_ip_allocate_option = "AUTO_ONLY" source_subnetwork_ip_ranges_to_nat = "LIST_OF_SUBNETWORKS" // Debug 用に設定を変更ください log_config { enable = true filter = "ERRORS_ONLY" } subnetwork { name = google_compute_subnetwork.proxy-client-subnet.self_link source_ip_ranges_to_nat = ["ALL_IP_RANGES"] } }
インスタンスの作成をします。外部IPアドレスを振らないため access_config {} はコメントアウトしています。(上記のネットワーク構成を設定しなかった場合はaccess_config {} のコメントを外して外部IPアドレスを設定するインスタンスで作成してください。)
また、Private Connection が必要な Cloud SQL へのアクセス用に Cloud SQL Auth Proxy クライアントのインストールスクリプトが入ってます。
resource "google_compute_instance" "datatream-priv-conn-postgres-proxy-instance" { project = "<YOUR_PROJECT_ID>" name = "datatream-priv-conn-postgres-proxy-instance" machine_type = "f1-micro" // 必要に合わせて変更ください zone = "<YOUR_ZONE>" // ネットワークの制限をするためのタグ // 下記 Firewall の設定で説明があります tags = [ "allow-datastream", ] boot_disk { initialize_params { image = "debian-cloud/debian-11" } } network_interface { network = google_compute_network.sample-datasource-vpc.self_link subnetwork = google_compute_subnetwork.proxy-client-subnet.self_link // 今回は外部IPアドレスは割り振らないので、access_configはコメントアウトしておく # access_config {} } // 事前にインストールしておく Cloud SQL Auth Proxy Agent の スクリプト // Cloud SQL Auth Proxy については以下のGCPのリンクを参照ください。 // https://cloud.google.com/sql/docs/postgres/sql-proxy metadata_startup_script = <<EOT #!/bin/sh apt-get update sudo apt-get install wget wget https://dl.google.com/cloudsql/cloud_sql_proxy.linux.amd64 -O cloud_sql_proxy chmod +x cloud_sql_proxy ./cloud_sql_proxy -instances=${google_sql_database_instance.private-instance.connection_name}:pg-source=tcp:0.0.0.0:5432 EOT // 作成したもしくは適した既存のサービスアカウントを登録ください service_account { email = "<YOUR_SA_EMAIL>" scopes = ["cloud-platform"] } depends_on = [ google_compute_network.sample-datasource-vpc, google_compute_subnetwork.proxy-client-subnet ] }
データソースへのアクセスを制限するための Firewallの設定として、3つの制限を入れています。
allow:通信 protocol と ports の制限souce_ranges:Datastream の プライベート接続設定に登録のある subnet のみからアクセス制限target_tags(ネットワーク タグ):同じタグが設定されている任意のリソースからのみのアクセス制限
Firewall の設定
resource "google_compute_firewall" "sample-datatream-priv-conn-postgres-fw" { project = "<YOUR_PROJECT_ID>" name = "sample-datatream-priv-conn-postgres-fw" network = google_compute_network.sample-datasource-vpc.name target_tags = [ "allow-datastream", ] // Debug 用に設定を変更ください log_config { metadata = "INCLUDE_ALL_METADATA" } allow { protocol = "tcp" ports = ["5432"] } source_ranges = [google_datastream_private_connection.datastream-priv-conn-postgres.vpc_peering_config.0.subnet] depends_on = [ google_compute_network.sample-datasource-vpc, google_datastream_private_connection.datastream-priv-conn-postgres ] }
インスタンスの作成が完了したら、PostgreSQL にアクセスしてシンクするための設定をします。
サンプルのため default である public の schema に作成していきます。テーブルは事前にテスト用のテーブルを作成してください。
// テーブル作成のSample Code CREATE TABLE sample_sync_test_tbl( id char(4) not null, name text not null, description text not null, PRIMARY KEY(id) );
publication と replication slot の作成
CREATE PUBLICATION sample_datastream_publication FOR TABLE public.sample_sync_test_tbl; SELECT PG_CREATE_LOGICAL_REPLICATION_SLOT('samples_datastream_replication_slot', 'pgoutput');
Datastream user の作成 と 権限の付与
CREATE USER sampledatastreamer WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD 'somepassword'; GRANT SELECT ON ALL TABLES IN SCHEMA public TO sampledatastreamer; GRANT USAGE ON SCHEMA public TO sampledatastreamer; ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO sampledatastreamer;
5. Datastream 接続プロファイルとストリームの設定
上記の設定が完了したら、最後に Datastream で 接続元と接続先のプロファイルをひとつずつストリームの設定をしていきます。
まずは接続元のデータソース情報をストリームの接続プロファイルを設定していきます。
解説の都合上、 postgresql_profile に接続情報を直で入れていますが、実際は運用に合わせて共有されない形で保管ください。
今回は上記で作成した Cloud SQL Auth Proxy Agent をインストールしたインスタンスを介して、Private Connection の制限がある Cloud SQL に接続するため、ホストネームとポート情報はインスタンスの設定に合わせます。
resource "google_datastream_private_connection" "datastream-priv-conn-postgres-profile" { project = "<YOUR_PROJECT_ID>" display_name = "datastream-priv-conn-postgres-profile" location = "<YOUR_REGION>" private_connection_id = "datastream-priv-conn-postgres-profile" postgresql_profile { // ホストには Proxy インスタンに割り当てられた network ip を設定してください hostname = google_compute_instance.datatream-priv-conn-postgres-proxy-instance.network_interface.network_ip port = 5432 username = "sampledatastreamer" password = "somepassword" database = "postgres" } vpc_peering_config { vpc = google_compute_network.dev-assured-vpc.id subnet = "10.2.0.0/16" } }
次に接続(同期)先の BigQuery のプロファイルを設定します。
resource "google_datastream_connection_profile" "datatream-bq-profile" { connection_profile_id = "datatream-bq-profile" display_name = "datatream-bq-profile" labels = {} location = "<YOUR_REGION>" project = "<YOUR_PROJECT_ID>" bigquery_profile {} timeouts {} }
最後にストリームの設定をします。
同期する範囲はテーブル単位の指定ができます。
BigQuery との同期データ鮮度(リアルタイム性)は data_freshness で設定可能です。
resource "google_datastream_stream" "datatream-stream-config" { desired_state = "NOT_STARTED" display_name = "datatream-stream-config" labels = {} location = "<YOUR_REGION>" project = "<YOUR_PROJECT_ID>" stream_id = "datatream-stream-config" backfill_all { } // 接続先の設定 destination_config { destination_connection_profile = google_datastream_private_connection.datatream-bq-profile.id bigquery_destination_config { data_freshness = "900s" // データの鮮度の設定 Default値 900s single_target_dataset { dataset_id = "<YOUR_BQ_DATASET_ID>" // Dataの接続先の Dataset id } } } source_config { source_connection_profile = google_datastream_private_connection.datastream-priv-conn-postgres-profile.id // postgresql_source_config { max_concurrent_backfill_tasks = 0 publication = "<YOUR_PQ_PUBLICATION_NAME>" replication_slot = "<YOUR_PQ_REPLICATION_SLOT_NAME>" include_objects { postgresql_schemas { schema = "public" // Postgres default値 ご自身の設定に合わせてください postgresql_tables { table = "<YOUR_BQ_DATASET_TBL_ID>" } } } } } timeouts {} }
作成されたストームは、管理コンソールで確認できます。また、停止、再開も管理コンソールからの操作が可能です。
停止した場合は、同期先の BigQuery が更新されず、データの鮮度の値が大きくなっていきます。また再開時は同期を取るため一度バックフィルを実行するようです。 バックフィルの設定が必要ですので、運用などに合わせて設定ください。


詳細ページでデータの鮮度に関してのメトリックスの確認も可能です。
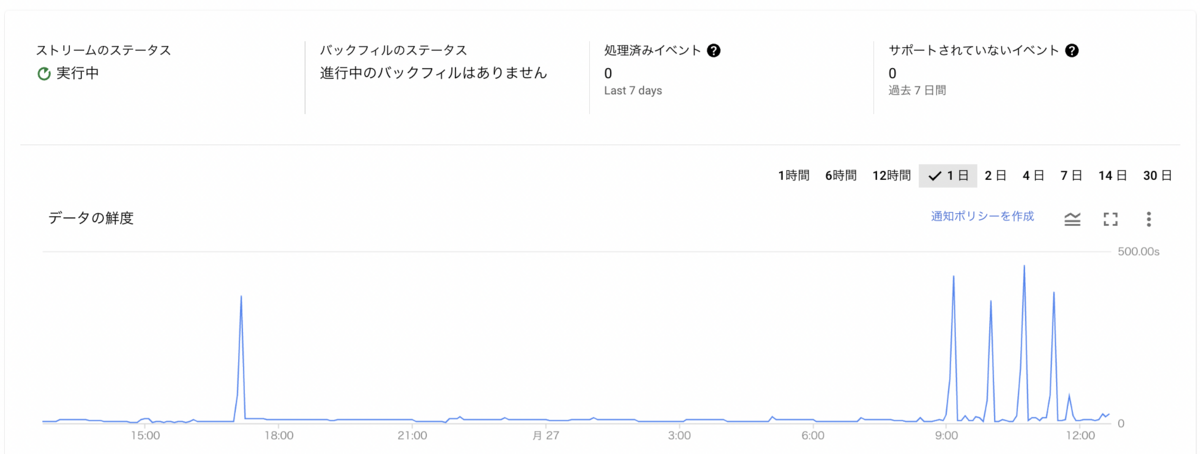
ストリームの設定が完了すれば、Datastream を使った Private Cloud SQL と BigQuery 同期構成の完了です。管理コンソールのメトリクスと合わせて、接続元の Cloud SQL でデータの追加、変更をして接続先の BigQuery での変更の同期を確認してみてください。
導入前に検討しておく注意点
Datastream の仕様・制限
Datastream はまだプレビューの機能などがあり導入前に個々のデータソースに対する制限を確認しておくのが無難です。 例えば、執筆時点(2023年3月)では PostgreSQLに関しては以下のいくつかの制限があります。(一部抜粋して記載しています。)
- テーブルやメモリに関しての制限
- ストリームは10,000テーブルに制限されます
- イベントには3MBのサイズ制限があります
- 検出できないデータ(構成)の変更
- 列を削除する
- 列のデータ型を変更する
- 列の順序を変更する
- テーブルを削除する(同じテーブルが新しいデータを追加して再作成された場合に関連する)
- 対応していない型 (
[Geometric](https://www.postgresql.org/docs/current/datatype-geometric.html),[Range](https://www.postgresql.org/docs/current/rangetypes.html),[Array](https://www.postgresql.org/docs/current/arrays.html), enumerated (ENUM), user-defined)
各他の Database の制限に関しては以下のリンクをご確認ください。
- PostgreSQLの制限
- MySQLの制限
- Oracleの制限
おわりに
導入時の Datastream for BigQuery はまだプレビューのサービスでしたがデータの活用の機会が高まっている中において、BigQuery 上に複数のデータソースからニア・リアルタイムに必要なデータを同期し集計や解析していくのに導入しやすいマネージドな CDC サービスです。 (2023年4月に Datastream の BigQuery と PostgreSQL のサポートが プレビューから GA なりました。Release Note も一緒に自身の使いたいサポートを確認していくのが良さそうです。)
Assured では、新規開発において多方面でできるだけお客様に安全かつスピーディな機能の提供を目指しながらも最新のトレンドや技術スタックを調べ、検証し、取り入れています。技術の選定から機能の提供まで一気通貫で裁量を持って作っていけるのは、今のフェーズならではなのかもしれませんね。Assured にご興味のある方はぜひ以下のカジュアル面談のリンクから申し込みください。(1年の振り返り記事もチームの雰囲気がわかる記事となっていますのでぜひ読んでみてください)
少し長い内容になりましたが、読んでいただきありがとうございます。